

Can We Predict the Retweet Status of Russian Troll Tweets?
Author: Katie Evanko-Douglas
Published: April 28, 2020
The short answer is, yes for tweets produced around the time of the 2016 election. No for tweets produced around the 2018 election. One reason for this might be that there is a statistically significant difference in the expression of the target variable between the two groups, meaning Russian trolls changed their re-tweet tactics enough between elections that the data we have for 2016 is not a good predictor for future election cycles.
The Data
The data set I chose for this project contains over 3 million tweets from handles associated with the Russian Internet Research Agency (IRA). It was provided by FiveThirtyEight and was downloaded from Kaggle. The code I wrote to subset the data-frame can be found on GitHub. The code I wrote to create and train the models can also be found on GitHub.
The original data-frame was split up between 9 CSVs. I first filtered each CSV to include only English-language tweets then took a random sample of 0.5% of each CSV and concatenated those to create a more manageable data-frame of a random sample of 10,646 English-Language IRA tweets.
Target: Retweet Status (0 if it was an original tweet and 1 if it was a re-tweet or quote-tweet.)
Baseline: 59% (59% of the tweets in the overall data-frame were original tweets.)
Evaluation Metric: Accuracy (The majority group constitutes < 70% of the data-frame so it is even enough to use accuracy.)
I avoided leakage by omitting the “post_type” column which listed whether the tweet was a re-tweet, quote-tweet, or neither.
Logistic Regression Model
I began with a logistic regression model using one hot encoding. This model yielded:
Training Accuracy: 86%
Validation Accuracy: 86%.
This was a 30-point improvement on my 56% baseline model.
Logistic Regression Confusion Matrix

For non-retweets, the model yielded:
Precision score: 96%
Recall score: 80%
F-1 score: 87%.
For retweets, the model yielded:
Precision score: 78%
Recall score: 95%
F-1 score: 86%
Random Forest Classifier
I then tried a random forest classifier model using ordinal encoding. This model yielded:
Training Accuracy: 93%
Validation Accuracy: 92%.
Random Forest Classifier Confusion Matrix

This was a 36-point improvement on my 56% baseline model.
For non-retweets, the model yielded:
Precision score: 95%
Recall score: 90%
F-1 score: 93%.
For retweets, the model yielded:
Precision score: 88%
Recall score: 94%
F-1 score: 91%
Final Model Testing
I chose the random forest classifier as my final model because of its overall accuracy gains. But when I tested it against my test data-set, comprised of the more recent tweets leading up to the 2018 election, the model failed to perform with such accuracy, instead yielding:
Overall Accuracy: 58%
This was a negligible increase over my baseline model of 56% and was much worse than how a simple majority classifier would’ve performed on the same data-set. (It was 72% original tweets, compared to 56% for the data-frame overall. A t-test between the two yielded a p-value of 1.9e-20).
Final Model Test Confusion Matrix

For non-retweets, the final model test yielded:
Precision score: 92%
Recall score: 45%
F-1 score: 61%.
For retweets, the final model test yielded:
Precision score: 39%
Recall score: 89%
F-1 score: 55%
Explaining the Model
I wanted to understand how my random forest classifier worked in order to figure out why it performed so poorly on future data. I started by looking at feature importances.
Feature Importances

The most important feature was the number of accounts the IRA account followed. Next came a tie between the number of followers the account had and the account category. I decided to take a deeper dive into these features. The most surprising feature was account category which showed something close to a Simpson’s paradox.
When looking at the whole data-frame, it appears that IRA trolls are twice as likely to retweet on a right-troll account compared to a left-troll account.
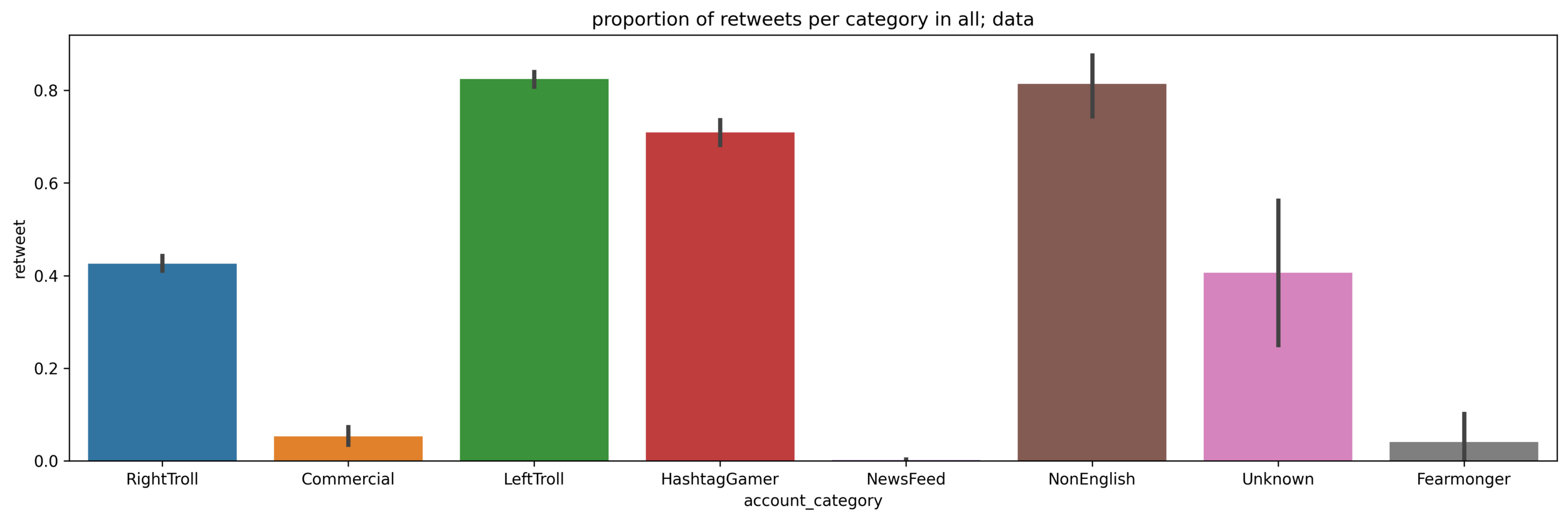
When we look at the training data by itself, this basic trend is mirrored.

But when we look at the more recent data used for testing, the trend is completely reversed, with right-troll accounts being roughly twice as likely to re-tweet as left-troll accounts.

It seems the model is not predicting future data well in part because the Russian trolls changed their focus and tactics between the 2016 and 2018 elections.
I decided to dive deeper into some other features to see if there were any patterns that were more consistent between them. It seems the interaction between followers and updates, for example, is more stable. The following graph represents the interaction of followers and updates in the validation group.

While the chart below represents the interaction of followers and updates in the test group.

The yellow squares represent a higher likelihood of retweets. The basic idea of both charts remains the same: Trolls are less likely to employ retweets when seeding an account but quickly shift gears as it begins to gain traction, using re-tweets to grow the account. When accounts have enough followers to be influential, they switch back to original tweets wherein they have a higher degree of control over the message.
Conclusions
In conclusion, creating predictive models around Russian troll tweets is difficult because they evolve their tactics quickly (they are still experimenting themselves) and we do not have very many years of data to work with. It’s a relatively new phenomenon.
Further study on this topic is needed to thoroughly differentiate between the underlying, stable strategies the IRA uses in every election from the short-term tactics they create for specific elections.
For example, it may be worth studying further whether the pattern of seeding an account with original tweets, growing with re-tweets, then influencing with original tweets is a stable enough pattern to be predictive.
Next Steps - Natural Language Processing
This study attempted to yield insights about IRA twitter activity purely from the quantitative aspects of IRA tweets. But the most interesting aspect of the tweets is their actual written content.
While that was beyond the scope of my initial data exploration, I am continuing to explore this topic using natural language processing techniques. I’ve build a prototype classifier using a TfidVectorizer and passive aggressive classifier but still have a long way to go in testing and explaining the model and its ethical implications before AmeliorMate is ready to release it as an official product for disinformation researchers.